
Kubernetes cluster mode
Kubernetes (https://kubernetes.io/) is an open source system that's used automate the deployment, scaling, and management of containerized applications. It was originally implemented at Google and then open sourced in 2014. The following are the main concepts of Kubernetes:
- Pod: This is the smallest deployable unit of computing that can be created and managed. A pod can be seen as a group of one or more containers that share network and storage space, which also contains a specification for how to run those containers.
- Deployment: This is a layer of abstraction whose primary purpose is to declare how many replicas of a pod should be running at a time.
- Ingress: This is an open channel for communication with a service running in a pod.
- Node: This is a representation of a single machine in a cluster.
- Persistent volume: This provides a filesystem that can be mounted to a cluster, not to be associated with any particular node. This is the way Kubernetes persists information (data, files, and so on).
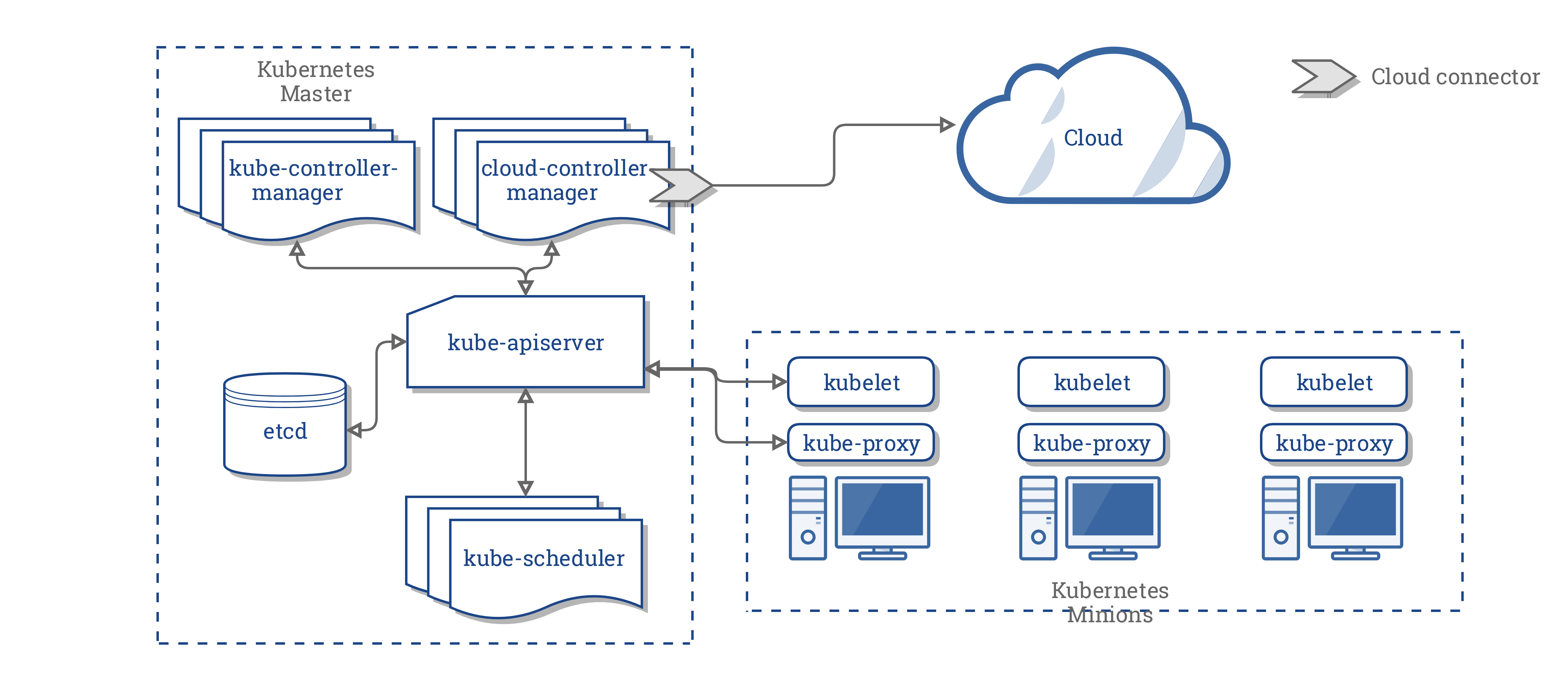
The following diagram (source: https://d33wubrfki0l68.cloudfront.net/518e18713c865fe67a5f23fc64260806d72b38f5/61d75/images/docs/post-ccm-arch.png) shows the Kubernetes architecture:
{kind=link}

The main components of the Kubernetes architecture are as follows:
- Cloud controller manager: It runs the Kubernetes controllers
- Controllers: There are four of them—node, route, service, and PersistenceVolumeLabels
- Kubelets: The primary agents that run on nodes
The submission of Spark jobs to a Kubernetes cluster can be done directly through spark-submit. Kubernetes requires that we supply Docker (https://www.docker.com/) images that can be deployed into containers within pods. Starting from the 2.3 release, Spark provides a Dockerfile ($SPARK_HOME/kubernetes/dockerfiles/Dockerfile, which can also be customized to match specific applications' needs) and a script ($SPARK_HOME/bin/docker-image-tool.sh) that can be used to build and publish Docker images that are to be used within a Kubernetes backend. The following is the syntax that's used to build a Docker image through the provided script:
$SPARK_HOME/bin/docker-image-tool.sh -r <repo> -t my-tag build
This following is the syntax to push an image to a Docker repository while using the same script:
$SPARK_HOME/bin/docker-image-tool.sh -r <repo> -t my-tag push
A job can be submitted in the following way:
$SPARK_HOME/bin/spark-submit \
--master k8s://https://<k8s_hostname>:<k8s_port> \
--deploy-mode cluster \
--name <application-name> \
--class <package>.<ClassName> \
--conf spark.executor.instances=<instance_count> \
--conf spark.kubernetes.container.image=<spark-image> \
local:///path/to/<sparkjob>.jar
Kubernetes requires application names to contain only lowercase alphanumeric characters, hyphens, and dots, and to start and end with an alphanumeric character.
The following diagram shows the way the submission mechanism works:

Here's what happens:
- Spark creates a driver that's running within a Kubernetes pod
- The driver creates the executors, which also run within Kubernetes pods, and then connects to them and executes application code
- At the end of the execution, the executor pods terminate and are cleaned up, while the driver pod still persists logs and remains in a completed state (which means that it doesn't use cluster computation or memory resources) in the Kubernetes API (until it's eventually garbage collected or manually deleted)